深入了解iptables proxy mode
最近在面試的時候,聽到主管問了面試者不少network request 如何到k8s service backend的問題,覺得可以整合一下網路上的資料,這篇主要討論iptables proxy mode。大部分的情況沒有在使用userspace proxy modes,ipvs proxy mode 可能要等下一次討論。
事前準備:
要先了解iptable工作機制,建議可以看這一篇:https://phoenixnap.com/kb/iptables-tutorial-linux-firewall
當然wikipedia也是寫得不錯,我下面的文字也大多引用https://zh.wikipedia.org/wiki/Iptables
快速帶過iptable
說到iptable要先了解Tables, Chains and Rules.
- Table 指不同類型的封包處理流程,總共有五種,不同的 Tables 處理不同的行為
raw: 處理異常,追蹤狀態 -> /proc/net/nf_conntrack
mangle: 處理封包,修改headler之類的
nat: 進行位址轉換操作
filter: 進行封包過濾
security: SElinux相關 - Chains 來對應進行不同的行為。像是“filter” Tables進行封包過濾的流程,而“nat”針對連接進行位址轉換操作。Chains 裡面包含許多規則,主要有五種類型的Chains
PREROUTING:處理路由規則前通過此Chains,通常用於目的位址轉換(DNAT)
INPUT:發往本機的封包通過此Chains。
FORWARD:本機轉發的封包通過此Chains。
OUTPUT:處理本機發出的封包。
POSTROUTING:完成路由規則後通過此Chains,通常用於源位址轉換(SNAT) - Rules 規則會被逐一進行匹配,如果匹配,可以執行相應的動作
大致的工作流向情況分兩種
1. backend為本機
NIC → PREROUTING → INPUT → Local process
Local process → OUTPUT → POSTROUTING → NIC2. backend目的地非本機
NIC→PREROUTING → FORWARD → POSTROUTING→NIC
下面是比較詳細的流程,有包含EBTABLES,但這個看久頭會昏,我這次會主要討論Network Layer 這一部分,然後用上面這張比較精簡的圖

Kube-proxy 修改了filter,nat兩個表,自定義了
KUBE-SERVICES,KUBE-NODEPORTS,KUBE-POSTROUTING,KUBE-FORWARD,KUBE-MARK-MASQ和KUBE-MARK-DROP,所以我這次會focus on filter,nat兩個Table
1. filter table有三個Chain “INPUT” “OUTPUT” “FORWARD”

kube-proxy在filter table的“INPUT” “OUTPUT” chain 增加了KUBE-FIREWALL在“INPUT” “OUTPUT” “FORWARD” chain 增加了KUBE-SERVICES
KUBE_FIREWALL會丟棄所有被KUBE-MARK-DROP標記0x8000的封包,而標記的動作可以在其他的table中(像是第二部分提到的NAT table中)


而filter table的KUBE-SERVICES可以過濾封包,假如一個service沒有對應的endpoint,就會被reject,這裡我先要建立一個service和沒有正確設定endpoint。
kind: Service
apiVersion: v1
metadata:
name: test-error-endpoint
namespace: default
spec:
ports:
- protocol: TCP
port: 7777
targetPort: 7777
---
kind: Endpoints
apiVersion: v1
metadata:
name: test-error-endpoint
namespace: defaultservice cluster ip 為 10.95.58.92
kind: Service
apiVersion: v1
metadata:
name: test-error-endpoint
namespace: default
selfLink: /api/v1/namespaces/default/services/test-error-endpoint
uid: 5d415d63-6fc3-444e-8b5a-29015b436a83
resourceVersion: '73026369'
creationTimestamp: '2020-11-17T05:48:52Z'
spec:
ports:
- protocol: TCP
port: 7777
targetPort: 7777
clusterIP: 10.95.58.92
type: ClusterIP
sessionAffinity: None
status:
loadBalancer: {}再次檢查iptable,就可以看到default/test-error-endpoint: has no endpoints -> tcp dpt:7777 reject-with icmp-port-unreachable

2. nat table有三個Chain “PREROUTING” “OUTPUT” “POSTROUTING”
在前兩個封包處理流程是比較相似和複雜的,大體來說是藉由客制化的規則,來處理符合條件封包,幫它們找到正確的k8s endpoint (後面會細講),在POSTROUTING主要是針對k8s處理的封包(標記0x4000的封包),在離開node的時候做SNAT
(inbound)在“PREROUTING”將所有封包轉發到KUBE-SERVICES
(outbound)在“OUTPUT”將所有封包轉發到KUBE-SERVICES
(outbound)在“POSTROUTING”將所有封包轉發到KUBE-POSTROUTING

當封包進入“PREROUTING”和“OUTPUT”,會整個被KUBE-SERVICES Chain整個綁架走,開始逐一匹配KUBE-SERVICES中的rule和打上標籤

kube-proxy 的用法是一種O(n) 算法,其中的 n 隨k8s cluster的規模同步增加,更簡單的說就是service和endpoint的數量。

我這裡會準備三個最常見的service type的kube-proxy路由流程
cluster IP
nodePort
load balancer
clusterIP流程:這裡我使用default/jeff-api(clusterIP: 10.95.57.19) 舉例,我下面圖過濾掉不必要的資訊

最後會到實際pod的位置,podIP: 10.95.35.31,hostIP: 10.20.0.128 是該pod所在node的ip
kind: Pod
apiVersion: v1
metadata:
name: jeff-api-746f4c9985-5qmw6
generateName: jeff-api-746f4c9985-
namespace: default
spec:
containers:
- name: jeff-api
image: 'gcr.io/jeff-project/jeff/jeff-api:202011161901'
ports:
- name: 80tcp02
containerPort: 80
protocol: TCP
nodeName: gke-sit-jeff-k8s-tw-01-default-pool-7983af35-ug91
status:
phase: Running
hostIP: 10.20.0.128
podIP: 10.95.35.31nodePort流程:這裡有一個關鍵就是KUBE-NODEPORTS 一定是在KUBE-SERVICES最後一項,iptables在處理packet會先處理ip為cluster ip的service,當全部的KUBE-SVC-XXXXXX都對應不到的時候就會使用nodePort去匹配。

我們看實際pod的資訊,podIP: 10.95.32.17,hostIP: 10.20.0.124 是其中一台node的ip
kind: Service
apiVersion: v1
metadata:
name: jeff-frontend
namespace: jeff-frontend
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 31929
selector:
app: jeff-frontend
clusterIP: 10.95.58.51
type: NodePort
externalTrafficPolicy: Cluster
---
kind: Pod
apiVersion: v1
metadata:
name: jeff-frontend-c94bf68d9-bbmp8
generateName: jeff-frontend-c94bf68d9-
namespace: jeff-frontend
spec:
containers:
- name: jeff-frontend
image: 'gcr.io/jeff-project/jeff/jeff-image:jeff-1.0.6.5'
ports:
- name: http
containerPort: 80
protocol: TCP
nodeName: gke-sit-jeff-k8s-tw-01-default-pool-b5692f8d-enk7
status:
phase: Running
hostIP: 10.20.0.124
podIP: 10.95.32.17load balancer流程:假如目的地IP是load balancer 就會使用 KUBE-FW-XXXXXX,我建立一個internal load balancer service 和 endpoint指到 google postgresql DB(10.28.193.9)

apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/load-balancer-type: Internal
networking.gke.io/internal-load-balancer-allow-global-access: 'true'
name: external-postgresql
spec:
ports:
- protocol: TCP
port: 5432
targetPort: 5432
type: LoadBalancer
---
apiVersion: v1
kind: Endpoints
metadata:
name: external-postgresql
subsets:
- addresses:
- ip: 10.28.193.9
ports:
- port: 5432
protocol: TCP
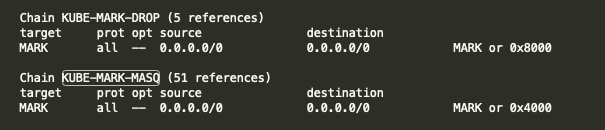
在NAT table看到KUBE-MARK-MASQ和KUBE-MARK-DROP這兩個規則主要是經過的封包打上標簽,打上標簽的封包會做相應的處理。KUBE-MARK-DROP和KUBE-MARK-MASQ本質上就是使用iptables的MARK指令
-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
如果打上了0x8000 到後面 filter table (上面提到KUBE_FIREWALL)就會丟棄。
如果打上了0x4000 k8s將會在PREROUTING table的 KUBE-POSTROUTING chain對它進行SNAT轉換。



Ref:
https://en.wikipedia.org/wiki/Netfilter
https://zh.wikipedia.org/wiki/Iptables
https://phoenixnap.com/kb/iptables-tutorial-linux-firewall
https://www.cnblogs.com/charlieroro/p/9588019.html
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/iptables/proxier.go
https://www.lijiaocn.com/%E9%A1%B9%E7%9B%AE/2017/03/27/Kubernetes-kube-proxy.html
https://juejin.im/post/6844904098605563912
https://tizeen.github.io/2019/03/19/kubernetes-service-iptables%E5%88%86%E6%9E%90/
https://www.hwchiu.com/kubernetes-service-ii.html
https://www.hwchiu.com/kubernetes-service-iii.html
https://www.itread01.com/content/1542712570.html
